Java Spark Dataset Encoder Example

Apache Spark Dataset Encoders Demystified
Encoders are like the secret sauce of Spark Dataset APIs which are becoming the default paradigm for Spark Jobs, and this article attempts to reveal the basic ingredients.
RDD, Dataframe, and Dataset in Spark are different representations of a collection of data records with each one having its own set of APIs to perform desired transformations and actions on the collection. Among the three, RDD forms the oldest and the most basic of this representation accompanied by Dataframe and Dataset in Spark 1.6.
However, with Spark 2.0, the use of Datasets has become the default standard among Spark programmers while writing Spark Jobs. The concept of Dataframe (in representing a collection of records as a tabular form) is merged with Dataset in Spark 2.0. In 2.0, a Dataframe is just an alias of a Dataset of a certain type. This popularity of Dataset is due to fact that they are being designed to provide the best of both RDD and the Dataframe world, flexibility, and compile type safety of RDDs along with efficiency and performance of Dataframes.
Central to the concept of Dataset is an Encoder framework that provides Dataset with storage and execution efficiency gains as compared to RDDs. Understanding the encoder framework is important in writing and debugging Dataset based Spark Jobs. Since each of the Dataset has to be associated with a type, whenever a Dataset of a certain type is created (from a file, collection of objects in RAM, RDD, or a Dataset), a corresponding Encoder of the same type has to be specified in the Dataset creation API(s). However, Specification of the encoder could be implicit in certain cases, such as of boxed primitive types.
An encoder of a particular type encodes either an Java object (of the encoder type) or a data record (in conformance with the data schema of the encoder type) into the binary format backed by raw memory and vice-versa. Encoders are part of Spark's tungusten framework. Being backed by the raw memory, updation or querying of relevant information from the encoded binary text is done via Java Unsafe APIs.
Spark provides a generic Encoder interface and a generic Encoder implementing the interface called as ExpressionEncoder . This encoder encodes and decodes (could be understood as serialization and deserialization also) a JVM Object (of type T) via expressions. Further, there is a factory available to users, viz., Encoders.
The Encoders factory provides storage efficient ExpressionEncoders for types, such as Java boxed primitive types (Integer, Long, Double, Short, Float, Byte, etc.), String, Date, Timestamp, Java bean, etc. Further, the factory also provides generic Java/Kryo serialization based ExpressionEncoder which can be used for any type so that the Encoders can be created for custom types that are not covered by storage efficient ExpressionEncoder.
Here is an example of a Java bean declared as TestWrapper
import java.io.Serializable;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.Map; public class TestWrapper implements Serializable {
private static final long serialVersionUID = 1L;
private Map<String, String> zap;
private ArrayList<String> strA;
private String name;
private String value;public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getValue() {
return value;
}
public void setValue(String value) {
this.value = value;
}
public Map<String, String> getZap() {
return zap;
}
public void setZap(Map<String, String> zap) {
this.zap = zap;
}
public ArrayList<String> getStrA() {
return strA;
}
public void setStrA(ArrayList<String> strA) {
this.strA = strA;
}
}
Storage/performance efficient ExpressionEncoder for the TestWrapper Java bean is declared as:
ExpressionEncoder<TestWrapper> en = Encoders.bean(TestWrapper.class) ExpressionEncoder for the TestWrapper can also be declared using Java/kryo serialization as below:
ExpressionEncoder<TestWrapper> en = Encoders.javaserialization(TestWrapper.class)
or
ExpressionEncoder<TestWrapper> en = Encoders.kryo(TestWrapper.class) Once, the ExpressionEncoder is created, it can be used to encode/decode an instance of TestWrapper to/from the binary format as shown below:
TestWrapper tw = new TestWrapper() /* To encode tw into binary format */
InternalRow row = en.toRow(tw) /* To decode tw from binary format */
Seq<Attribute> attr = en.resolveAndBind$default$1();
TestWrapper tw =
en.resolveAndBind(attrs,sparkSession.sessionState().analyzer()).fromRow(row);
InternalRow abstracts the stored binary coded format and exposes methods to query and update fields stored in the binary format as shown below:
row.numFields() /* Outputs number of fields stored in the binary format */
row.getString(0) /* Outputs the value of the name field in the TestWrapper instance tw stored in the binary format row */ The number of fields in the binary format is in accordance with the schema interpreted in a particular ExpressionEncoder. For example, the number of fields is 4 when Java bean ExpressionEncoder is used for TestWrapper, while there would be only 1 field if Java/kyro serializer based ExpressionEncoder is used.
In serialized based ExpressionEncoders, the whole object is serialized based on either Java or Kryo serialization and the serialized byte string is kept as the only single field in the encoded binary format, therefore these lack storage efficiency and one cannot directly query particular fields of the object directly from the encoded binary format.
On the other hand,
In Java bean based ExpressionEncoders, the bean object is mapped to the binary format by just keeping its fields in the binary format thereby providing twin benefits of storage efficiency and faster querying of individual fields. Therefore, for Datatsets composed of complex datatypes, one should always construct datatype as Java bean consisting of fields for which Encoders factory supports non-serialized based ExpressionEncoders.
Below is the picture of binary format which an Encoder outputs
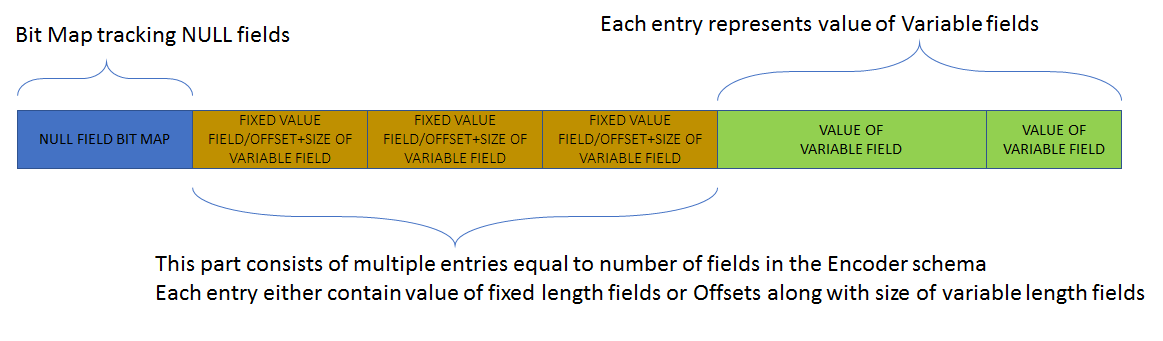
As shown above, there is a NULL bitmap at the start to efficiently detect NULL values for certain fields. This is followed by a fixed-length entries section, where each entry corresponds to a field and the number of entries equal to the number of fields. Each of these entries either contains values for fixed-length fields or contains value offset (in the variable section) and value length. The variable section at the last contains values of variable length fields.
An Illustration of space savings obtained via storage efficient encoders is given below.


In the above illustration, Firstly, an RDD was created out of 1 Lakh objects of a Person bean (consisting of fields Id, Name, Age) and cached in memory to measure the memory size. Secondly, a Dataset was created using bean encoder (ExpressionEncoder ) out of the same 1 Lakh objects of the Person bean and then cached in memory to measure memory size. Comparing the memory size of the two, Dataset clearly reflects the memory advantage.
To recap, here are the 3 broad benefits provided by Encoders empowering Datasets to their present glory:
Storage efficiency: Dataset Encoder provides storage efficiency for widely used Java types. Therefore, Datasets can be easily cached in memory for performance gains. Also, the readily available binary format enables efficient storage of Datasets on disk (without the need for JAVA/Kryo serializer).
Query efficiency: Since the layout of data fields is well defined within the binary format of the Encoder, data fields can be directly queried from the efficiently encoded binary format of objects stored on disk. On the other hand, if objects are stored in serialized forms on disk, then for the querying its fields, the object has to be deserialized in memory first which is highly inefficient.
Shuffle efficiency: During the shuffle, data objects move from one partition to another via the network. This movement generally requires serialization and deserialization of data via Java/Kryo serializers. However, since Dataset encoder already encodes the object into a compact well-defined binary format, no further explicit serialization required. Since the Dataset encoders storage efficiency is way ahead of the conventional serializers, the amount of shuffle data in the case of Dataset wide transformations becomes magnitude lesser than in the case of RDDs. A reduced amount of shuffle data in turn increases the reliability and performance of the shuffle stage.
In case you have more queries regarding the encoders, please feel free to write in the comment section.
Also, here is the link to my recently published book covering Spark partitioning in depth:
https://www.amazon.com/Guide-Spark-Partitioning-Explained-Depth-ebook/dp/B08KJCT3XN
Source: https://towardsdatascience.com/apache-spark-dataset-encoders-demystified-4a3026900d63
0 Response to "Java Spark Dataset Encoder Example"
Post a Comment